System Design - Scalable URL Shortener
Scalable URL Shortener System Design
Tech Stack: FastAPI MySQL Redis Docker
Going beyond simple feature implementation, this URL Shortener system is architected to support 100 million DAU. This post documents the insights gained from designing and building a service similar to bit.ly and TinyURL from scratch.
1. Functional Requirements
Core functionalities are defined by extracting verbs from the problem statement.
| Operation | Description | API |
|---|---|---|
| Create | Accept a long URL and return a unique shortened URL | POST /api/urls/shorten |
| Redirect | Redirect to the original URL when a short URL is accessed | GET /api/urls/{shortUrl} |
| Track | Asynchronously track click counts for each shortened URL | Internal event handling (private) |
2. Non-Functional Requirements
Quality constraints are defined by extracting adjectives from the problem statement.
| Constraint | Description |
|---|---|
| High Availability | 24/7 uninterrupted service even under massive traffic |
| Low Latency | Fast redirect response within 10ms |
| Uniqueness | Zero collision between generated short URLs |
| High Durability | Data persistence guaranteed even through server failures |
Scale Estimation
- Read/Write ratio: 100:1 (Read-Heavy system)
- Daily write requests: ~1 million
- Data retention period: 5 years
- Size per entry: ~500 bytes
3. Data Model
Entities are defined by extracting nouns from the problem statement. A Decoupled Architecture was adopted, physically separating URL mapping and Analytics data for performance optimization.
| Table | Role | Key Attributes |
|---|---|---|
| URLMapping | Original-to-short URL mapping | id(PK), short_url(Unique Index), original_url, created_at |
| Analytics | Click count and statistics | id(PK), short_url_id(FK), click_count |
The two tables have a 1:1 relationship and are managed as independent services to isolate analytics traffic from impacting redirect performance.

4. Core Algorithm: ID Generation & Base62 Encoding
Why Not Hashing?
Several candidates were evaluated when selecting an ID generation strategy.
| Approach | Pros | Cons |
|---|---|---|
| Hash Function | Simple to implement | Collision risk, requires collision resolution logic |
| UUID | Guarantees global uniqueness | 128-bit length is too long for “shortening” purposes |
| Snowflake ID | Time-ordered, supports distributed environments | High implementation complexity |
| Machine ID + Sequence | Simple, collision-free, naturally integrates with sharding | Requires machine count limits |
The final choice was Machine ID + Sequence Number, with the generated integer encoded in Base62.
Base62 Encoding
- Mechanism: Integer ID → Base62 Encoding → Short String (e.g.,
123456→FXsk) - Character set:
[a-z, A-Z, 0-9]= 62 characters - Capacity: $62^7 \approx 3.5 \times 10^{12}$ (~3.5 trillion) unique URLs, sufficient for 5+ years of data
Base62 was chosen over Base64 because + and / can be interpreted as special characters in URLs — only URL-safe characters are used.
5. High-Level Architecture
The complete flow including Redis caching and Docker orchestration.
Write Path
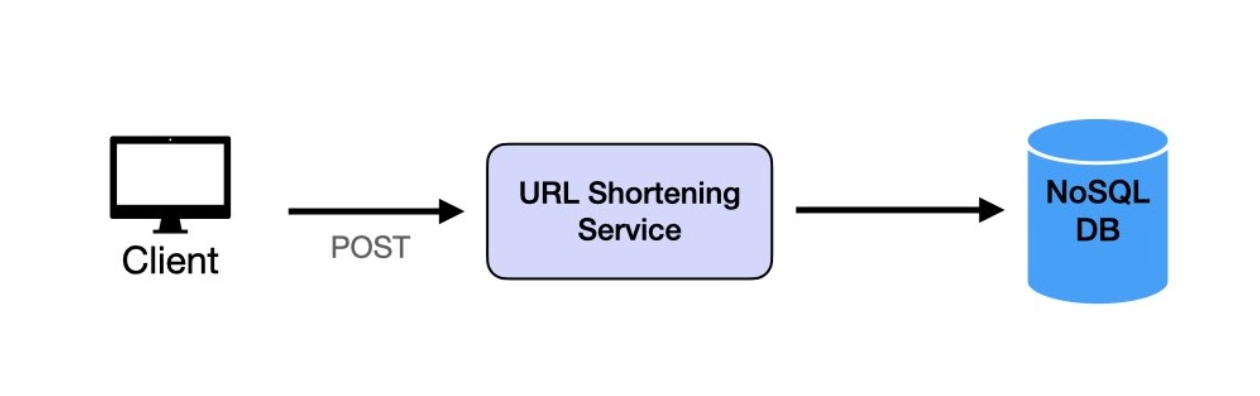
- Client sends a long URL via
POST /api/urls/shorten - URL Shortening Service requests a unique ID from the ID Generator
- ID is Base62-encoded to create the short URL
- Mapping is stored in the URLMapping table and the short URL is returned
Read Path

- A
GETrequest is made with the short URL - Cache First: Look up the mapping in Redis (respond immediately on hit)
- Cache Miss: Query the DB for the original URL → update Redis cache
- Respond with
302 Foundto redirect to the original URL
Analytics Path
Redirect occurs → Message Queue (Kafka) → Analytics Service → In-Memory Counter (Redis) → DB Flush
Click counts are updated asynchronously via a Message Queue without blocking the main redirect logic. Real-time aggregation is performed using Redis in-memory counters, which are periodically flushed to the DB.
6. Scaling Strategy
Using Machine ID as Shard Key
By using the first character of the short URL as the Machine ID (Prefix), the ID Generator and DB shards are mapped 1:1.
- Write: Each machine independently generates IDs and writes only to its own shard → fully parallel processing
- Read: The prefix of the short URL instantly determines which shard to query (e.g.,
a82c7w→ sharda) - Scale: Adding a new machine with a unique prefix enables horizontal scaling with zero impact on existing systems
Key benefits of this architecture:
| Benefit | Description |
|---|---|
| Scalability | Horizontal scaling by simply adding machines |
| Concurrency | Independent write paths maximize throughput |
| Isolation | A single shard failure does not affect the entire system |
| Simplicity | Maintenance tasks (backup, indexing) performed per shard |
7. Deep Dive: Engineering Insights
301 vs 302 Redirect Strategy
| Status Code | Behavior | Characteristics |
|---|---|---|
| 301 Moved Permanently | Browser caches the result | Reduces server load, cannot collect analytics |
| 302 Found | Every request passes through the server | Enables analytics collection, increases server load |
302 Found was chosen so the server can receive every request and collect statistics. Since analytics is a core requirement, every click must be recognized by the server.
Caching Optimization
Following the 80/20 Rule (Pareto Principle), 80% of total traffic concentrates on the top 20% of popular URLs. By applying a read-through caching pattern:
- Redis receives requests first; on cache miss, it automatically queries the DB and stores the result
- The Request Handler does not need to manage cache miss logic directly
- Maximizes memory efficiency while ensuring $O(1)$ lookup performance
Infrastructure Automation
MySQL and Redis are operated as isolated containers via Docker Compose, ensuring environment consistency and deployment reproducibility.
8. Summary & Reflection
Expectations by Level
| Dimension | Mid-Level | Senior | Staff |
|---|---|---|---|
| ID Generation | Explain uniqueness and shortness requirements | Compare Hash/UUID/Snowflake with trade-offs | Multi-region ID coordination, clock skew handling |
| Encoding | Explain Base62 and calculate ID space | Discuss Base16/62/64 trade-offs | Encoding implications for analytics and debugging |
| Scaling | Understand sharding concepts | Design shard key strategy, read routing | Hot shard handling, Consistent Hashing |
| Caching | Include cache layer in design | Calculate cache hit ratios, invalidation strategy | Multi-tier caching, Cache Stampede prevention |
Key Lesson
System Design goes beyond “code that works” — you must be able to explain “why this architecture was chosen.” A URL Shortener may seem simple, but every decision — ID generation strategy, caching layers, sharding strategy, redirect method — involves trade-offs. Recognizing these trade-offs and making choices with clear rationale is the essence of system design.
Leave a comment